4 мин чтения · 13 февраля 2026
Исследование того, как эффективно использовать систему агентного управления состоянием на базе LangGraph.
Введение
Переход от простых LLM-оберток к автономным агентным системам — это следующий рубеж GenAI. Однако с автономией приходит риск непредсказуемости. Перевод агента из демо-версии в промышленную эксплуатацию требует не только остроумных промптов и рабочих процессов; необходима надежная структура управления (governance framework). В этом посте мы исследуем, как использовать MLflow для создания «клетки управления» — системы версионирования, гранулярной оценки и проактивного мониторинга, которая гарантирует надежность ваших агентов, оставляя при этом открытыми некоторые вопросы для размышления.
У каждого проекта свой дизайн, компромиссы и цели — универсального решения не существует. В конечном счете, все сводится к тому, что вы приоритезируете больше: надежность или автономию.
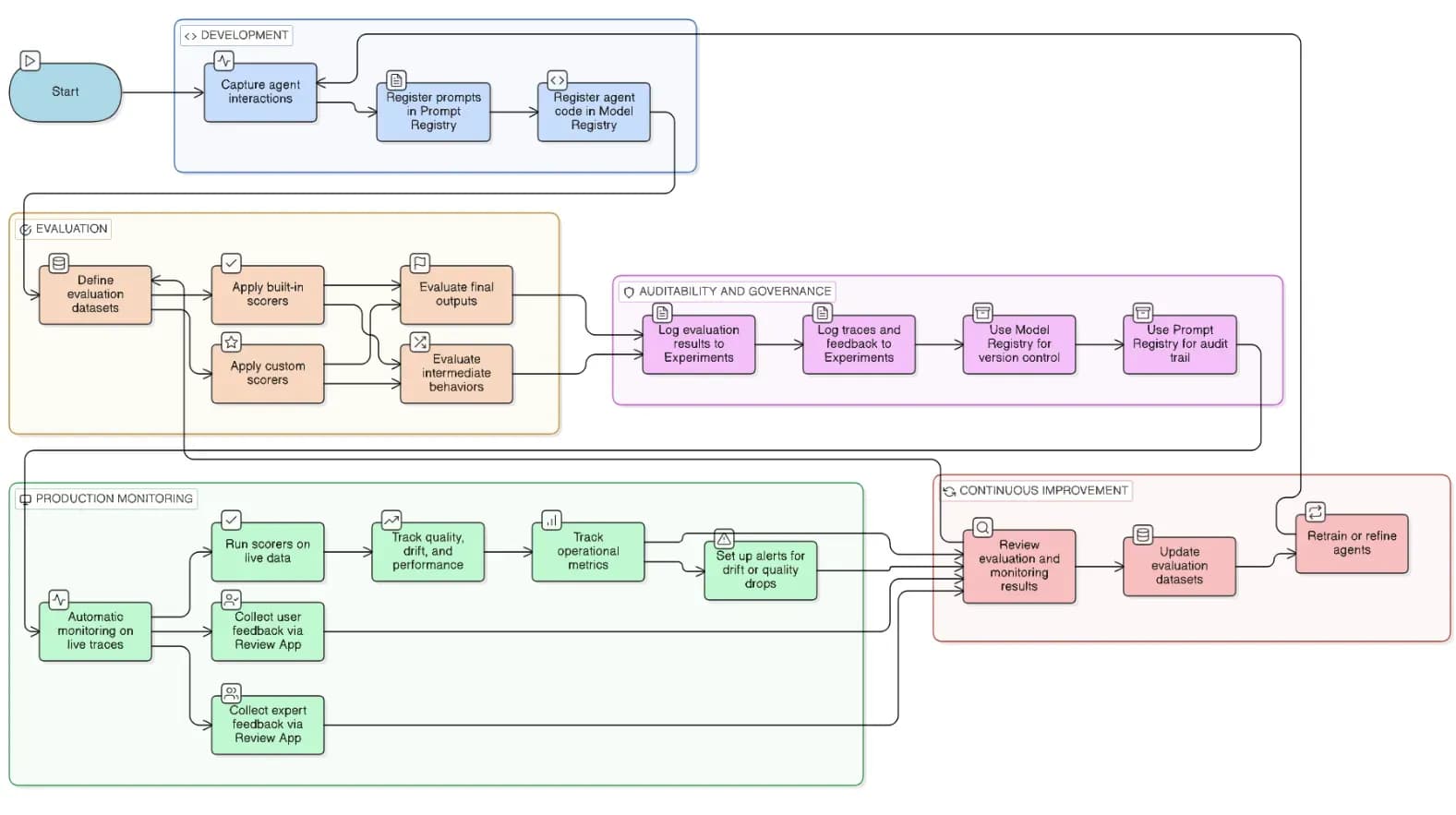
1. Версионирование и воспроизводимость: подход «сначала реестр»
При создании агентных приложений относитесь к промптам, моделям и логике агентов как к версионируемым активам, а не как к жестко закодированным скриптам, которые остаются только в вашем ноутбуке.
- Реестр промптов (Prompt Registry): Итерируйте и тестируйте промпты в MLflow Playground. Отделив промпты от кода, вы сможете мгновенно откатиться назад или безопасно экспериментировать без переразвертывания всего приложения.
- Версионирование датасетов: Храните входные данные (переменные для инъекции) и ожидания (ground truths) в стандартизированных форматах, таких как Pandas DataFrames, чтобы обеспечить последовательное бенчмаркинг и логирование в MLflow.
- Реестр моделей (Model Registry): Регистрируйте как логику агента, так и лежащую в основе LLM. Это гарантирует, что конкретная версия вашего агента воспроизводима, тестируема и легко поддается аудиту.
Используйте фреймворки типа DSPy для оптимизации промптов относительно датасетов на основе GEPA (Generic Evolutionary Prompt Algorithms) или других упомянутых методов для программного уточнения поведения.
2. Матрица оценки
Оценка агента значительно сложнее, чем оценка чат-бота. Вы должны оценивать и цель, и путь. Выбор метрик (scorers), типов оценки и уровня гранулярности должен руководствоваться удобством и практичностью, а не теоретическими соображениями. Система должна развиваться, не становясь «узким местом».
Метрики (Scorers)
-
Встроенные метрики: Используйте стандартные показатели корректности (Correctness), безопасности (Safety) и обоснованности поиска (Retrieval Groundedness).
-
Кастомные метрики: Проверки, специфичные для бизнеса (например, поиск PII или логика на базе regex).
-
Статические метрики: Жесткие пороги операционного здоровья, такие как задержка (Latency) или стоимость токенов.
-
Безреференсные (Reference-Free): Идеально для бизнес-логики, где нет «идеального» эталона. Используется подход «LLM-as-a-Judge» с заданными порогами.
-
На основе референсов (Reference-Dependent): Критически важно для задач с высокими ставками, где вывод должен соответствовать «золотому стандарту» датасета (это очень чувствительно к обновлению данных и промптов).
Гранулярность оценки
- Финальный результат (Final Output): Фокусируется на том, является ли итоговый ответ правильным, полезным или безопасным.
- Траектория (Trajectory): Анализирует пошаговое выполнение узлов, вызов инструментов и промежуточные действия (например, использовал ли агент нужный инструмент поиска перед суммаризацией?). Это важно для обеспечения эффективности и снижения галлюцинаций.
- Одиночный шаг (Single Step): Оценивает отдельные шаги принятия решений (например, привел ли конкретный запрос к выбору правильного инструмента). Работает как юнит-тест для когнитивных способностей агента.
Хотя это обеспечивает структурированный путь, это остается экспериментальной средой; поскольку отраслевые стандарты для агентных систем все еще созревают, этот жизненный цикл служит скорее базой для минимизации рисков, а не абсолютной гарантией соответствия.
3. Мониторинг в продакшене и Human-in-the-Loop
Когда агент запущен, одних логов недостаточно — нужны трассировки (traces). Мониторинг в MLflow позволяет отслеживать:
- «Витальные показатели»: Задержка, частота запросов и уровень ошибок.
- «Железо»: Использование CPU/RAM и потребление токенов.
- Контекст: Кастомные теги, такие как
datasource_queriedилиresponse_length. - Оценки: Постоянная проверка соответствия (alignment) на живых данных.
Human-in-the-Loop (HITL): Интеграция обратной связи напрямую в трассы (с помощью mlflow.log_feedback) создает петлю непрерывного улучшения. Позволяя пользователям ставить оценки «палец вверх/вниз» или оставлять комментарии, вы помечаете пути выполнения для ручного обзора, закрепляя ИИ в человеческих суждениях и этике.
4. Открытый вопрос: Дрейф рассуждений vs Дрейф данных
Как измерять дрейф, когда «истина» динамична? В агентной системе мы сталкиваемся с тремя типами «зыбучих песков»:
- Волатильность API: Данные реального времени меняются поминутно.
- Эволюция RAG: База знаний обновляется ежедневно.
- Свежесть SQL: Таблицы баз данных обновляются с разной периодичностью (еженедельно/ежемесячно).
В таких средах «неправильный» ответ сегодня мог быть «правильным» вчера. Каждая команда должна определить свой допуск на отклонение (Tolerance for Variance). Для погодного приложения разница в 2 градуса приемлема; для финансового аудитора расхождение в 0,01% — это провал.
Заключительные мысли
Создание агентов корпоративного уровня — это построение надежной структуры для прослеживаемости и модульной оценки. Успешное внедрение ИИ основано на доверии. Внедряя автоматизированные системы оценки и сохраняя человека в контуре управления («control plane»), мы гарантируем, что ИИ останется инструментом прогресса, а не источником неуправляемого риска.
Комментарии (0)